Debugging targets pipelines

Will Landau
Why targets?
- Manage computationally demanding work in R:
- Bayesian data analysis: JAGS, Stan, NIMBLE,
greta
- Deep learning:
keras, tensorflow, torch
- Machine learning:
tidymodels
- PK/PD:
nlmixr, mrgsolve
- Clinical trial simulation:
rpact, Mediana
- Statistical genomics
- Social network analysis
- Permutation tests
- Database queries:
DBI
- Big data ETL
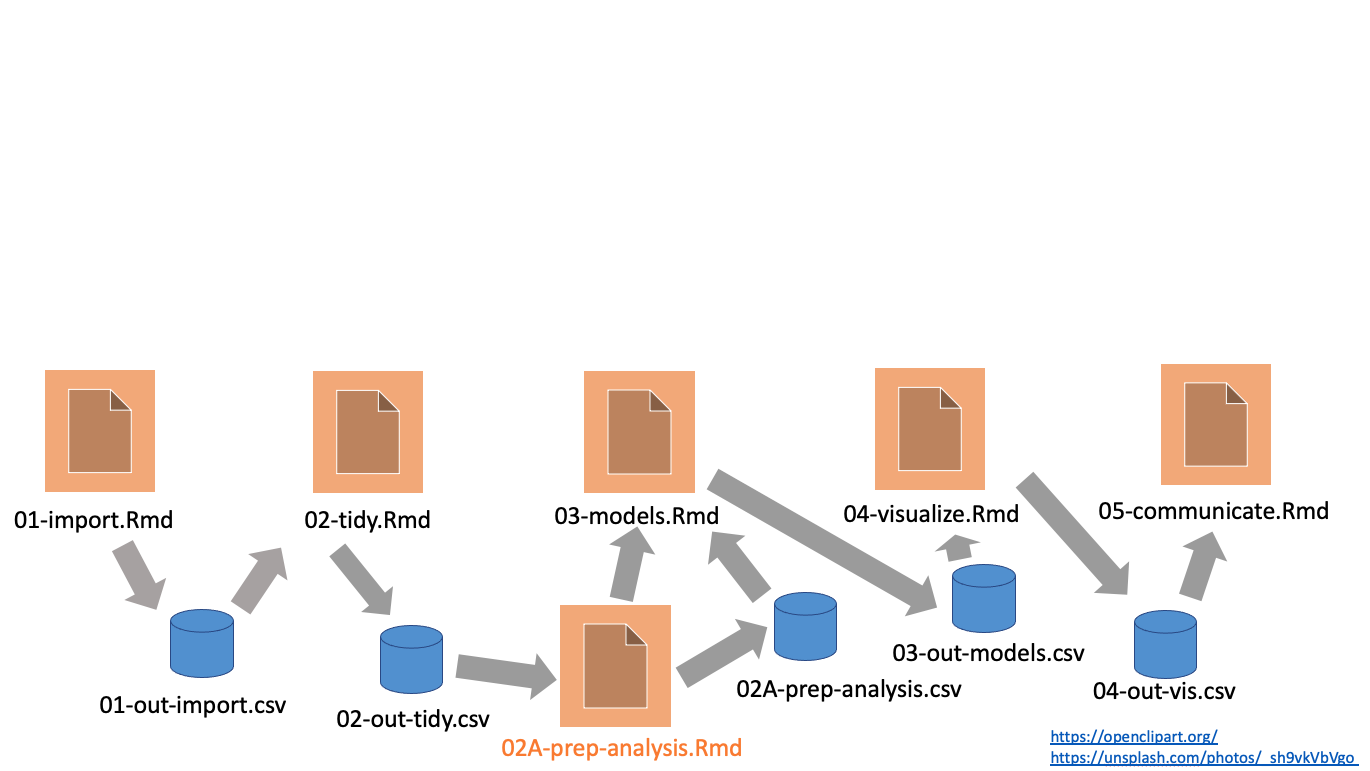
Typical notebook-based project
![]()
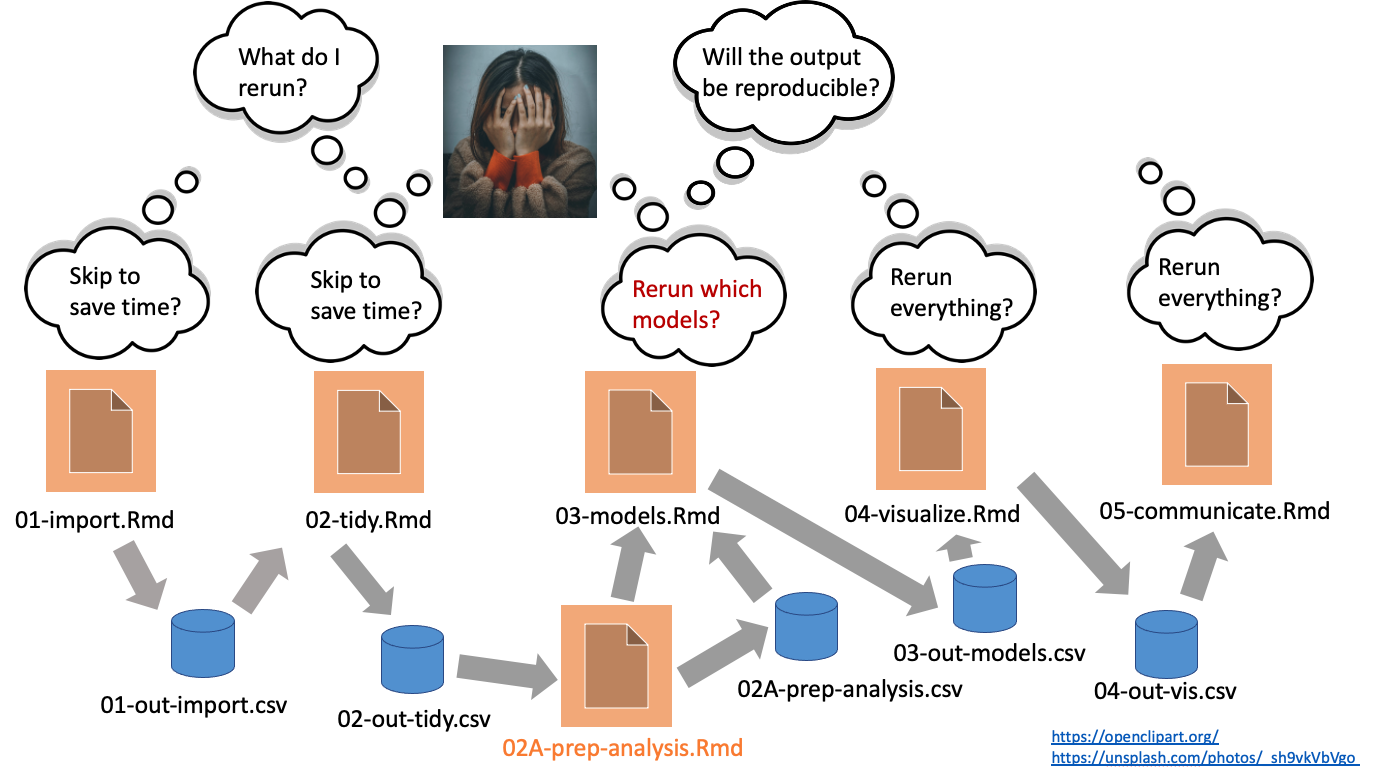
Messy reality: managing data
![]()
Messy reality: managing change
![]()
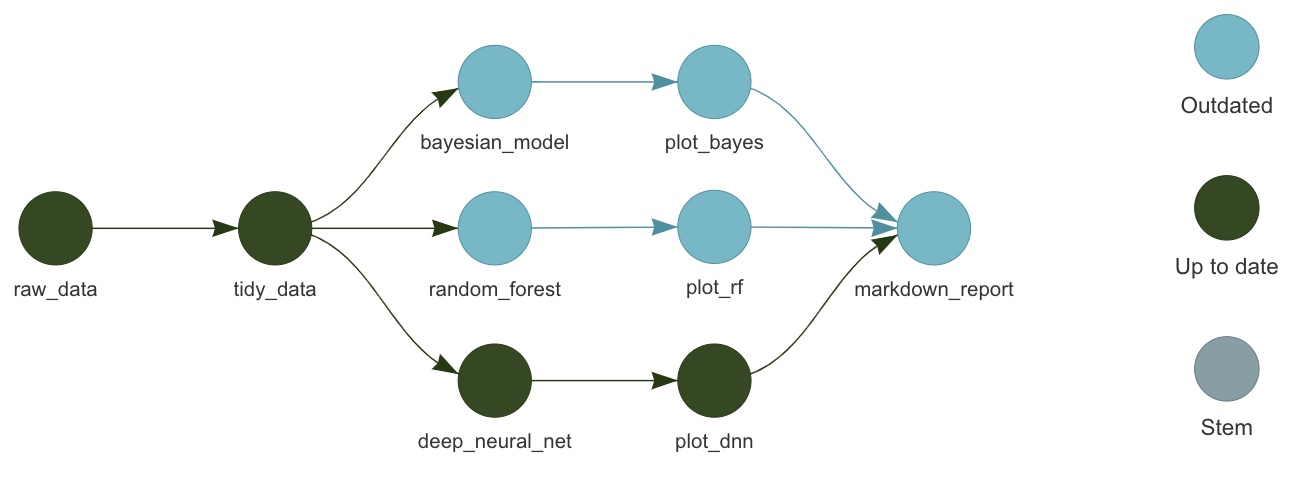
targets
![]()
- Designed for R.
- Encourages good programming habits.
- Automatic dependency detection.
- Behind-the-scenes data management.
- Distributed computing.
Resources
![]()
Extensions to {targets}
![]()
- Ecosystem of packages to support literate programming, Bayesian data analysis, etc. in
targets.
- Compatible with other tools such as
renv, Quarto, R Markdown, Shiny, pins, and vetiver.
Debugging: challenges
- R code is easiest to debug in the interactive console.
- To ensure reproducibility and to manage heavy computation, a pipeline is automated and non-interactive.
- External
callr::r() process
- Data management
- Environment management
- High-performance computing
- Error handling
Debugging: techniques
- Finish the pipeline anyway.
- Inspect error messages.
- Debug functions.
- Check for system issues.
- Pause the pipeline with
browser().
- Pause the pipeline with the
targets debug option.
- Save a
targets workspace.